
Protocols are the lifeblood of modern systems. But as applications scale, logs often grow into endless walls of text—loud, repetitive, and overwhelming. Finding the root cause of a timeout or misconfiguration can feel like looking for a needle in a haystack.
This is where our AI-powered log analysis solution comes into play. Introduced in NVIDIA's Generative AI Reference Workflows, the Log Analysis Agent combines a Retrieval-Augmented Generation (RAG) pipeline with a graph-based multi-agent workflow to automate log parsing, relevance scoring, and self-correcting queries.
In this post, we examine the architecture, key components, and implementation details of the solution. Instead of drowning in protocol dumps, developers and operators can get straight to the “why” behind the errors.
Who needs a protocol analysis agent?
- QA and test automation teams: Pipeline testing generates large logs that are often difficult to analyze. Our AI system supports log summarization, clustering, and root cause detection, helping QA engineers quickly pinpoint broken tests, faulty logic, or unexpected behavior.
- Engineering and DevOps teams: Engineers work with heterogeneous log sources – application, system, service – all in different formats. Our AI agents unify these streams, perform hybrid retrieval (semantics and keyword), and display the most relevant snippets. The result: faster root cause identification and fewer nighttime firefights.
- CloudOps and ITOps teams: Cloud environments increase complexity through distributed services and configurations. AI log analysis enables cross-service ingestion, centralized analysis, and early anomaly detection in the event of misconfigurations or bottlenecks.
- Platform and Observability Manager: For leaders driving observability, visibility is everything. Instead of floods of raw data, our solution delivers clear, actionable summaries that help prioritize bug fixes and improve the product experience.
Introduction to the Protocol Analysis Agent architecture
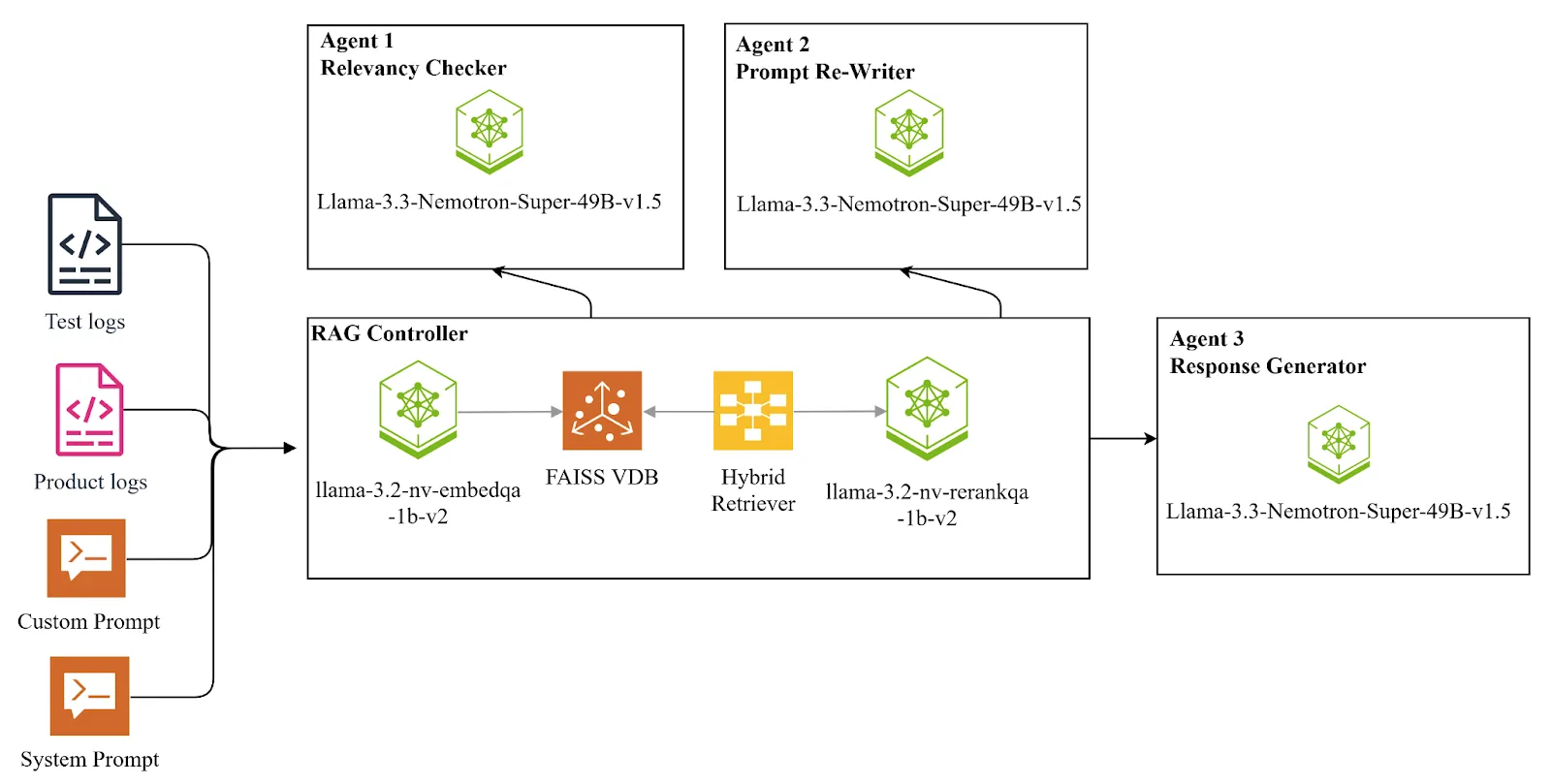
The Protocol Analysis Agent is a self-correcting, multi-agent RAG system designed to extract insights from protocols using large language models (LLMs). It orchestrates a LangGraph Workflow that includes:
- Hybrid retrieval: BM25 for lexical matching + FAISS vector storage with NVIDIA NeMo Retriever embeddings for semantic similarity.
- Reclassification: NeMo Retriever reorders the results to show the most relevant log lines.
- Grading: Candidate snippets are evaluated for their contextual relevance.
- Generation: Generates contextual responses instead of raw log dumps.
- Self-correction loop: If the results are not sufficient, the system rewrites the queries and tries again.
Multi-agent intelligence: divide, conquer, correct
The solution implements a directed graph where each node is a specialized agent: retrieval, reordering, ranking, generation or transformation. Edges encode decision logic to dynamically control workflow.
- agents act independently in certain subtasks.
- Conditional edges Make sure the system adjusts and returns to self-correction when necessary.
Key components:
| component | file | Purpose |
| StateGraph | bat_ai.py | Defines the workflow diagram using LangGraph |
| node | graphnodes.py | Implements fetching, reranking, ranking, generation and query transformation |
| Edge | graphedges.py | Encodes the transition logic |
| Hybrid Retriever | multiagent.py | Combines BM25 and FAISS retrieval |
| Output models | binary_score_models.py | Structured output for grading |
| Utilities | utils.py and prompt.json | Prompts and NVIDIA AI endpoint integration |
All source files are available in the GenerativeAIExamples GitHub repository.
Behind the Scenes: Retrieval, Reclassification, and Self-Correction
Hybrid retrieval:
The Hybrid driver class in multiagent.py united:
- BM25 Retriever for precise lexical evaluation.
- FAISS Vector Store For semantic similarity, embeddings from an NVIDIA NeMo Retriever model (llama-3.2-nv-rerankqa-1b-v2) are used.
This dual strategy balances precision and recall, ensuring that both keyword matches and semantically related log snippets are captured.
LLM integration and reassessment:
Command prompt templates are loaded from prompt.json They lead each LLM assignment. NVIDIA AI endpoint performance:
These models are orchestrated within workflow nodes to seamlessly handle retrieval, reassessment, and response generation.
Self-correction loop:
If the initial retrieval results are weak, the transform_query The node rewrites the user's question to refine the search. Conditional edges such as decide_to_generate And grade_generation_vs_documents_and_question Evaluate results. Based on the evaluation, the workflow either proceeds to final response generation or returns to the retrieval pipeline for another pass.
Quick guide
Clone the repo:
git clone https://github.com/NVIDIA/GenerativeAIExamples.git
cd GenerativeAIExamples/community/log_analysis_multi_agent_rag
Run a sample query:
python example.py --log-file /path/to/your.log --question "What caused the timeout errors?"
The system is running Retrieval → Reranking → Grading → Generation provide a clear explanation of the source of the error.
Make it yours: customization and extensions
- Fine-tune: Exchange custom LLMs or customize prompts for your protocols.
- Industry adjustments: Similar multi-agent workflows already support cybersecurity pipelines and self-healing IT systems.
- Cross-domain potential: Quality Assurance, DevOps, CloudOps and Observability can all benefit.
From Protocols to Insights: Why It Matters
The Log Analysis Agent demonstrates how multi-agent RAG systems can transform unstructured logs into actionable insights, reducing mean time to resolution (MTTR) and improving developer productivity:
- Faster debugging: Diagnose problems in seconds, not hours.
- Smarter root cause detection: Contextual answers, not raw dumps.
- Cross-domain value: Adaptable for quality assurance, DevOps, CloudOps and cybersecurity.
Beyond log analysis
This is just the beginning. The same multi-agent workflow that enables log analysis can be extended to:
- Automation of error reproduction: Convert protocols into small cases.
- Observability dashboards: Merge logs, metrics and traces.
- Cybersecurity pipelines: Automating anomaly and vulnerability checks.
Try it yourself: Run the sample query on your logs and discover how Multi-Agent RAG can transform your debugging workflow. Fork, expand and deploy your own agents – the system is modular.
Curious about how generative AI and NVIDIA NeMo Retriever are used? Discover more examples and applications.
References
Learn more
For hands-on learning, tips and tricks, join our Nemotron Labs live streams.
Stay up to date on Agentic AI, Nemotron and more by subscribing to NVIDIA news, joining the community and following NVIDIA AI on LinkedIn, Instagram, X and Facebook.
Discover more video tutorials and live streams for self-study here.